機械学習モデルを構築した後に、そのモデルの性能を正確に評価し、改善するプロセスは、機械学習の成功において非常に重要です。モデルが高い精度を持っているかどうかを判断するには、適切な評価指標とテスト方法を理解し、モデルの過学習やデータに対する過度な適合を防ぐことが必要です。本章では、モデルの評価と改善の手法について、詳しく解説します。
5.1 モデル評価指標(精度、F1スコア、混同行列)
モデルがどれほど正確に予測を行っているかを測定するためには、いくつかの評価指標を使用することができます。代表的な評価指標として、精度(Accuracy)、F1スコア(F1 Score)、そして混同行列(Confusion Matrix)があります。これらの指標を理解し、適切に使い分けることは、モデルの性能を的確に評価するために欠かせません。
5.1.1 精度(Accuracy)
精度は、正しく分類されたサンプルの割合を表す評価指標です。以下のように計算されます。
.png)
Pythonでは、scikit-learnのaccuracy_score関数を使用して精度を計算することができます。
from sklearn.metrics import accuracy_score
# 予測ラベルと実際のラベルを比較して精度を計算
accuracy = accuracy_score(y_true, y_pred)
print(f'Accuracy: {accuracy:.2f}')
精度は非常に直感的で分かりやすい指標ですが、クラスの不均衡があるデータセットでは、精度だけでは不十分です。たとえば、99%がクラスAで、1%がクラスBであるデータセットでは、常にクラスAを予測するモデルでも99%の精度を達成できますが、これはクラスBを無視しているために有用なモデルとはいえません。
5.1.2 混同行列(Confusion Matrix)
混同行列は、モデルの予測結果を可視化し、どのクラスがどれだけ正確に分類されたかを理解するのに役立ちます。混同行列は以下の4つの要素から構成されます。
- TP(True Positive): 正例を正しく予測した数
- TN(True Negative): 負例を正しく予測した数
- FP(False Positive): 負例を誤って正例と予測した数(偽陽性)
- FN(False Negative): 正例を誤って負例と予測した数(偽陰性)
混同行列は次のように視覚化されます。
| 実際の正例 | 実際の負例 | |
|---|---|---|
| 予測の正例 | TP | FP |
| 予測の負例 | FN | TN |
これに基づいて、他の評価指標も計算することができます。Pythonではconfusion_matrixを使用して混同行列を生成できます。
from sklearn.metrics import confusion_matrix
# 予測ラベルと実際のラベルを使って混同行列を生成
cm = confusion_matrix(y_true, y_pred)
print(cm)
この混同行列を使って、次に説明するF1スコアや精度、再現率などの他の指標を計算できます。
5.1.3 精度(Precision)、再現率(Recall)、F1スコア(F1 Score)
精度(Precision)は、モデルが予測した正例のうち、実際に正しかった割合を示します。つまり、偽陽性の影響を測定します。
.png)
一方、再現率(Recall)は、実際の正例のうち、モデルが正しく予測できた割合を示します。偽陰性の影響を測定します。
.png)
F1スコアは、精度と再現率の調和平均で、これら2つのバランスを取るための指標です。特にクラス不均衡のあるデータセットで有用です。
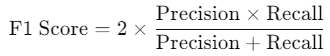
Pythonではprecision_score、recall_score、f1_scoreを使用してこれらを計算できます。
from sklearn.metrics import precision_score, recall_score, f1_score
# Precision, Recall, F1 Scoreの計算
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f'Precision: {precision:.2f}')
print(f'Recall: {recall:.2f}')
print(f'F1 Score: {f1:.2f}')
F1スコアは、精度と再現率のバランスが求められるシナリオで特に有効です。例えば、医療データのように誤った診断を防ぐことが重要な場合、F1スコアが有用です。
5.2 クロスバリデーションとハイパーパラメータのチューニング
機械学習モデルの性能を最大限に引き出すためには、ハイパーパラメータの最適化とモデルの汎化能力を高めるための適切な評価方法が重要です。ここでは、クロスバリデーション(交差検証)とハイパーパラメータのチューニング方法について詳しく説明します。
5.2.1 クロスバリデーション(交差検証)
クロスバリデーションは、データを複数の部分に分け、それぞれを訓練データとテストデータとして使用することで、モデルの汎化性能を評価する手法です。これにより、データセット全体のバランスを考慮した評価が可能になります。
最も一般的な方法はk分割交差検証(k-fold cross-validation)です。この手法では、データをk個の等しい部分に分割し、1つをテストデータ、残りを訓練データとして使用するというプロセスをk回繰り返します。最終的なモデルの性能は、k回の評価結果の平均として計算されます。
Pythonでは、scikit-learnのcross_val_scoreを使用してクロスバリデーションを実行できます。
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
# ランダムフォレストモデルの定義
model = RandomForestClassifier()
# k=5のクロスバリデーションを実行
scores = cross_val_score(model, X, y, cv=5)
print(f'Cross-validation scores: {scores}')
print(f'Average score: {scores.mean():.2f}')
クロスバリデーションは、データ量が少ない場合や、過学習のリスクを避けたい場合に特に有用です。
5.2.2 ハイパーパラメータのチューニング
モデルのパフォーマンスを最大限に引き出すためには、適切なハイパーパラメータを選ぶ必要があります。ハイパーパラメータは、モデルの学習プロセスに影響を与える設定値で、モデル自体の訓練中には調整されないパラメータです。たとえば、ランダムフォレストの木の数やSVMのカーネルの種類などがこれに該当します。
ハイパーパラメータの最適化には、グリッドサーチ(Grid Search)やランダムサーチ(Random Search)などの手法があります。
グリッドサーチは、あらかじめ定義したパラメータの範囲をすべて試す手法です。一方、ランダムサーチは指定された範囲からランダムにパラメータを選び、試行回数を減らしつつ最適なパラメータを見つけます。
Pythonでは、GridSearchCVやRandomizedSearchCVを使用してハイパーパラメータのチューニングを行うことができます。
from sklearn.model_selection import GridSearchCV
# パラメータの候補を定義
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [10, 20, 30],
'min_samples_split': [2, 5, 10]
}
# ランダムフォレストモデルの定義
model = RandomForestClassifier()
# グリッドサーチを使用して最適なパラメータを探索
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X, y)
# 最適なパラメータとスコアを表示
print(f'Best parameters: {grid_search.best_params_}')
print(f'Best score: {grid_search.best_score_:.2f}')
ハイパーパラメータのチューニングは、モデルの性能を大幅に向上させることができるため、特に大規模なデータセットや複雑なモデルでは不可欠です。
5.3 過学習とその対策
過学習(Overfitting)とは、モデルが訓練データに対して過度に適応してしまい、テストデータや新しいデータに対しては性能が低下する現象です。これは、モデルがデータのノイズや特定の特徴に過剰に反応してしまうために起こります。
過学習を防ぐためには、次のような対策が有効です。
5.3.1 正則化(Regularization)
正則化は、モデルが極端な重みを持たないように制約を加えることで、過学習を抑制する方法です。正則化には、L1正則化(Lasso)とL2正則化(Ridge)があります。
- L1正則化(Lasso): モデルの重みをゼロにすることで、特徴量選択の役割を果たします。
- L2正則化(Ridge): 重みが非常に大きくなることを防ぎ、全体のバランスを保ちます。
Pythonでは、scikit-learnのLassoやRidgeを使用して正則化を適用できます。
from sklearn.linear_model import Ridge
# L2正則化を適用した線形回帰モデル
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)
print(f'Coefficients: {model.coef_}')
5.3.2 ドロップアウト(Dropout)
ドロップアウトは、特にニューラルネットワークで使われる過学習防止の手法で、訓練中にランダムに一部のニューロンを無効にすることで、モデルが特定の経路に依存しないようにします。
PythonのKerasやTensorFlowなどのライブラリで簡単にドロップアウトを適用できます。
from keras.layers import Dropout
from keras.models import Sequential
from keras.layers import Dense
# ドロップアウトを含むニューラルネットワークの定義
model = Sequential()
model.add(Dense(128, input_dim=64, activation='relu'))
model.add(Dropout(0.5)) # 50%のユニットを無効にする
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# モデルのコンパイルと訓練
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
ドロップアウトは過学習のリスクを減らす有効な手法で、特に深層学習においてモデルの汎化能力を向上させます。
5.3.3 データの増強(Data Augmentation)
データ増強は、主に画像やテキストデータに対して使用される手法で、既存のデータに対して小さな変換(回転、拡大縮小、フリップなど)を加え、データセットの多様性を増やすことで過学習を防ぎます。
例えば、画像データでは回転やスケール変換を行うことで、元の画像から新しいバリエーションを生成し、モデルにとってより多様なデータを与えることができます。Kerasを使用して画像データ増強を行う例を示します。
from keras.preprocessing.image import ImageDataGenerator
# 画像データ増強を行うための設定
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
# 画像データに対してデータ増強を適用
datagen.fit(X_train)
# モデルの訓練
model.fit(datagen.flow(X_train, y_train, batch_size=32), epochs=50)
データ増強を行うことで、モデルはより多様なデータに対して適応しやすくなり、過学習を防止できます。データ増強は特に画像認識や自然言語処理の分野で多く使われています。
5.3.4 早期終了(Early Stopping)
早期終了(Early Stopping)は、訓練データに対する精度が向上していても、検証データに対する精度が向上しなくなった時点で訓練を終了する手法です。これにより、過学習が発生する前にモデルの訓練を止めることができます。
早期終了は、深層学習モデルや反復的なアルゴリズムでよく使用され、モデルが過学習する前に最適な重みを保存するために有効です。KerasではEarlyStoppingコールバックを使用して簡単に実装できます。
from keras.callbacks import EarlyStopping
# 早期終了の設定(検証データの損失が改善しなくなったら訓練を停止)
early_stopping = EarlyStopping(monitor='val_loss', patience=5)
# モデルの訓練
model.fit(X_train, y_train, epochs=100, batch_size=32, validation_split=0.2, callbacks=[early_stopping])
この手法では、指定したエポック数の間に検証データの損失が改善しない場合に訓練が停止され、最も性能の良い状態のモデルが保存されます。これにより、過学習を抑制しつつ最適なモデルを得ることが可能です。
5.3.5 クロスバリデーションを用いた評価の強化
前述のクロスバリデーションは、モデルの評価と改善においても強力なツールです。モデルが訓練データに過剰に適応していないかを判断するために、異なるデータセットを使ってモデルの性能を評価することができます。これにより、モデルの過学習を確認し、必要に応じて調整することができます。
まとめ
本章では、機械学習モデルの評価と改善に関する主要な手法について解説しました。評価指標として精度、F1スコア、混同行列を理解し、さらにクロスバリデーションやハイパーパラメータのチューニングを通じてモデルの性能を最大限に引き出す方法を学びました。また、過学習の防止手法として、正則化、ドロップアウト、データ増強、早期終了などの手法を紹介し、これらを適切に組み合わせることで、モデルの汎化能力を向上させることが可能です。
機械学習におけるモデルの評価と改善は、単に精度を上げることではなく、過学習を防ぎながら、将来の未知のデータに対しても優れた性能を発揮できるようにすることが重要です。